Defensive Programming - Friend or Foe?
One of the worst things about embedded development (especially in C) is
receiving a return value of -1 or unknown_error from a function, with no
other information about why the failure took place. It provides no information
about where the error bubbled up from!
We’ve all been here as embedded developers, bringing up new boards, drivers, modules, and applications, wondering why and how we got into this mess. Root causing these issues is like peeling an onion: each layer we dig through while debugging, we smile a bit less and a few more tears are shed. These sorts of issues are often a result of developer error, either calling functions out of order, at the wrong time, or with incorrect arguments. They could also be because the system was in a bad state, such as out of memory or deadlocked.
The firmware knows there is an issue, and it likely knows what the issue is, but yet it doesn’t help solve the issue. The software was built with “Defensive Programming” practices in mind, which allows for the firmware to keep running even when incorrect behavior occurs.
Usually, I would prefer that the firmware crash, print a useful error, and guide me exactly to where the issue is. This the guiding principle of “Offensive Programming”, which goes one step further than “Defensive Programming”.
In this article, we’ll dive into what defensive and offensive programming are, where defensive programming falls short, how developers should think about using them within embedded systems, and how the techniques of offensive programming can surface bugs and help developers root cause them immediately at runtime.
By taking defensive and offensive programming to the extreme, you’ll be able to track down those 1 in 1,000-hour bugs, efficiently root cause them, and keep your end-users happy. And, as a bonus, keep your sanity.
To learn more about offensive and defensive programming best practices and ask me questions live, register for our webinar on February 24, 2022.
Table of Contents
Defensive Programming
Defensive programming is the practice of writing software to enable continuous
operation after and while experiencing unplanned issues. A simple example is
checking for NULL after calling malloc(), and ensuring that the program
gracefully handles the case.
void do_something(void) {
uint8_t *buf = malloc(128);
if (buf == NULL) {
// handle this gracefully!
}
}
Defensive programming sounds nice, and it is nice! The firmware that we write should never catastrophically fail due to unforeseen circumstances if we don’t want it to.
Defensive programming really shines when interacting directly with hardware, proprietary libraries, and external inputs that we don’t have direct control over. Hardware may have glitches or behave differently in various environments, heavyweight libraries often are riddled with bugs, and the outside world will send whatever it wants over communication protocols.
As with most things, defensive programming can be abused and the benefits become outweighed by the negatives. If many modules are layered on top of one another, each using defensive programming techniques, bugs can and will be created, lost, and/or obscured.
Problems with Defensive Programming
The key to defensive programming is to use it at the exterior interfaces of your firmware. There should be a thin but sturdy wall of defensive programming between the outside world and hardware, and then the majority of your code inside the walls should be more aggressively checking for errors and yelling at developers when they do the wrong thing.
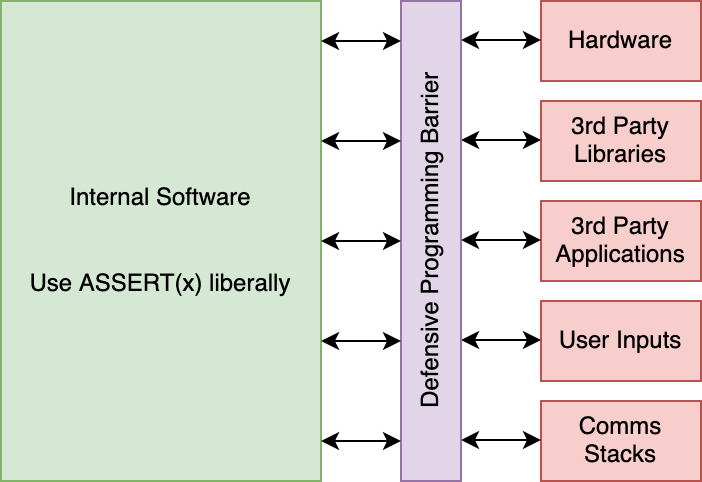 If code paths originate from or pass through the red zones, then defensive programming is a good approach.
If code paths originate from or pass through the red zones, then defensive programming is a good approach.
For instance, let’s assume we have an internal function,
hash32_djb2(const char *str, size_t len), which takes in the string we should
hash and a length. This function is never going to be directly used by any
external consumers, which leaves only internal developers.
By having a check and return value like the following:
uint32_t hash32_djb2(const char *str, int len)
{
if (str == NULL) {
// Invalid argument
return 0;
}
...
You are only shooting yourself and your fellow developers in the feet. If any
developer passes a NULL string to this function, it will return 0 and be
stored as a valid hash!
The NULL string argument is likely the developer’s own bug, and they should
immediately become aware of the bug, or else it might slip into production.
This practice of writing code to aggressively surface errors is what is known as “Offensive” Programming. (Merriam Webster definition #1, “making attack”)
Offensive Programming
Offensive programming, although seemingly opposite in word choice, actually
expands upon defensive programming and takes it one step further. Instead of
just accepting that malloc() can fail, software with offensive programming in
mind might assert that malloc() never fails. If a malloc() call does fail,
the software fatally assert, print enough information for the developer to root
cause the issue or capture a core dump, and then reset it back to a known
working state.
In embedded systems, where the entire stack from hardware to software is often built and controlled by a single organization, any bug is the responsibility of the engineers in that organization to root cause and fix. Offensive programming can be a useful approach to surface bugs that might otherwise take weeks to reproduce or never be found.
Offensive programming can take many forms inside of software, but the most common way is to use assertions liberally and creatively against developer errors and system state behavior.
Let’s run through a few hypothetical situations and how you could use offensive programming. If your embedded system is experiencing:
- Performance issues - such as the GUI freezing or slow response times to button presses, you can use watchdogs or timers and assertions to crash the system when the system stalls so that a developer can figure out what exactly was consuming CPU time.
-
Memory issues - such as high stack usage, no free heap memory, or
excessive fragmentation, trigger a crash of the system when these states are
detected and capture the relevant parts for analysis by a developer to figure
out where the system went sideways. It’s rarely the final call to
malloc()or the highest function in the stack that pushes the system over the edge, but everything that led up to it. -
Locking issues - set a low-ish timeout (5 seconds) on RTOS functions, such
a
mutex_lockandqueue_put. Setting a low timeout will cause the system to crash if the operation did not succeed in the allotted time, again allowing a developer to further inspect what was the root issue. You can also choose to spin indefinitely and have the watchdog clean up.
This is just scratching the surface of offensive programming techniques, but I hope you now have an idea of what this article is all about!
Benefits of Offensive Programming
You might be asking why you should instrument your code and firmware with a bunch of asserts, timers, watchdogs, and coordinated faults, and that’s a reasonable question. Software crashes on an embedded system don’t just take down a thread, but often the entire system as well.
There are two sides to this double-edged sword.
On one hand, when the device experiences unforeseen issues, you can leave the system running in an undefined and unpredictable state. Maybe the heap is out of memory, or the system failed to put a critical event in a queue and we’ve dropped data, or maybe a thread has deadlocked and there is no automated recovery mechanism. Some devices don’t even have power buttons and need to be manually unplugged or the batteries pulled out!
On the other hand, devices in an unintended state are essentially broken devices and should be reset. If the device was out of heap, it likely isn’t going to recover and there exists a leak. If a thread has deadlocked, it also isn’t going to recover. Not to mention, running in an undefined state leaves firmware open to security holes and is exactly what we want to avoid.
On top of preventing your firmware from running in an unpredictable state, triggering asserts and faults at the exact moment of the bug helps developers track down these issues! If your devices are connected to a debugger while an assert or fault is hit, or you have core dump instrumentation, you can reap the following benefits:
- Quicker bug fixes - If the system is halted or a core dump is captured when an assert is hit, the developer can get access to backtraces, registers, function arguments, and system state such as the heap, lists, and queues. With all this information, developers can root cause issues more quickly.
-
Faster development - Writing a new piece of code that integrates into
multiple modules can be tricky if there are bugs or assumptions in the modules
you are integrating with. By having assertions and OffP practices in the
surrounding layers, if a developer does anything misaligned with the API
specs, the system will immediately alert the developer. It’s better than
tracking down what
-3orunknown_errormeans and how it bubbled up through the system. - Awareness of prevalence - Developers don’t notice bugs unless they are obvious or dropped in their inbox as a bug report. By forcing the software to reset, awareness of these unknown bugs is increased and developers can more easily understand how often they are occurring.
- Returning system to sane state - If your comms thread is deadlocked, no data will be sent from your device to the outside world, making your device a brick until a user manually resets it. By resetting the device, you are more likely to put the device back into a functioning state. Most embedded devices have very quick reboot times, so it isn’t a huge deal.
Offensive Programming in Practice
Let’s dig into some concrete examples of bugs we can find using offensive programming practices.
Argument Validation
If a developer tries to use an API and passes invalid arguments into the
function, make sure the application yells at them to fix the issue. There is
nothing worse than receiving a -1 return value and digging through 10 layers
of firmware code only to find out the real reason was that you passed in a
string of 20 characters when the maximum was 16 or because you accidentally
passed a null pointer due to an uninitialized variable.
void device_set_name(char *name, size_t name_len) {
ASSERT(name && name_len <= 16);
...
}
The only time I would choose, or at least heavily debate, to not use asserts to
validate arguments is when I am building a library that will be used by people
outside of my organization. In those cases, I would make the validation asserts
optional, just as FreeRTOS does with their RTOS functions by allowing developers
to define configASSERT themselves1.
Resource Depletion
Although using dynamic memory in embedded systems is sometimes frowned upon, it is often necessary for complex systems that don’t have enough static memory to go around. Even when dynamic memory is used, running out of memory should rarely occur. When memory is low, systems should adapt and put back pressure on any data flowing into the system and rate-limit memory-intensive operations.
However, if a firmware does deplete the dynamic memory pool, we want to know when and why it happened! It could be a memory leak or an accidental allocation that consumed most of the heap. Running out of memory might not be a show-stopping issue because the system might recover, but if we are in the development or internal testing phase, let’s find out why we ran out!
To do this, we can add an assert inside of a malloc() function that verifies
that the call did not fail.
void *malloc_assert(size_t n) {
void *p = malloc(n)
ASSERT(p);
return p;
...
}
In code where the calls to malloc() should never fail, such as for the
allocation of RTOS primitives, request and response buffers, etc., we can use
this asserted version.
Another common issue with RTOS-based systems is a queue becoming full due to not being processed quickly enough. As with memory depletion, this isn’t a show-stopping issue because the system might recover, but we could very well be dropping events that are critical to the operation of the device! This is an issue that should be investigated and ideally prevent from ever happening.
We can add an ASSERT() to confirm that each queue insertion succeeded, or
maybe even wrap that function if we want.
void critical_event(void) {
...
const bool success = xQueueSend(q, &item, 1000 /* wait 1s */)
ASSERT(success);
...
}
To help with the debugging process of a queue full, I highly suggest writing a Python GDB script to dump the contents of the queue. Then, when the system is halted or you have a core dump allowing you to find out what events were consuming the majority of the space in the queue!
(gdb) queue_print s_event_queue
Queue Status: 10/10 events in queue (FULL!)
0: Addr: 0x200070c0, event: BLE_PACKET
1: Addr: 0x200070a8, event: TICK_EVENT
2: Addr: 0x20007088, event: BLE_PACKET
3: Addr: 0x20007070, event: BLE_PACKET
4: Addr: 0x20007050, event: BLE_PACKET
5: Addr: 0x20007038, event: BLE_PACKET
6: Addr: 0x20007018, event: BLE_PACKET
7: Addr: 0x20007000, event: BLE_PACKET
8: Addr: 0x20006fe0, event: BLE_PACKET
9: Addr: 0x20006fc8, event: BLE_PACKET
Looks like our queue was full of packets from our comms stack and we weren’t processing them quickly enough. We now know where the issue is and we can find a solution.
Software Stalls & Deadlocks
Embedded devices need to respond in a reasonable amount of time to user input and communication packets all while being performant and not showing any signs of lag or stalls.
I can’t count the number of times while working on previous projects that slow flash operations caused the system to freeze for 2-3 seconds at a time, wreaking havoc on the user experience or causing other operations in the system to time out. The worst part about these issues is that they often aren’t brought to developers’ attention until it’s too late.
To help catch these issues before pushing firmware to external users, you can create and configure your task watchdogs to be more aggressive, set up timers to assert after a few seconds during potentially long operations, and make sure to set timeouts on your threading system calls.
To assert that a mutex was successfully locked, we can pass a timeout into most RTOS calls and assert that it succeeded.
void timing_sensitive_task(void) {
// Task watchdog will assert a stall
const bool success = mutex_lock(&s_mutex, 1000 /* 1 second */);
ASSERT(success);
{
...
}
}
Or, if a task watchdog is configured to detect stalls, you can just wait indefinitely!
void timing_sensitive_task(void) {
// Task watchdog will assert a stall
mutex_lock(&s_mutex, INFINITY);
{
...
}
}
Since a hiccup and stall here and there isn’t the end of the world, when you build the final image that you’ll push to customers, you can either tune down or (gasp!) remove these checks altogether.
Use After Free Bugs
After a buffer allocated with malloc() is free()‘ed, it should never be used
again by software. However, it happens all the time. This bug is aptly named a
“Use After Free” bug2. If the system re-uses a buffer that was
freed, there’s a good chance nothing bad will happen. The system will happily
use the buffer and write and read data from it.
However, sometimes, it will result in memory corruption and present itself in the strangest of ways. Memory corruption bugs are notoriously difficult to debug.
If you are struggling with memory corruption issues, you might want to read this section on catching memory corruption bugs from a previous post.
One way to help prevent use-after-free bugs is to scrub the entire contents of the memory with an invalid address that, when accessed, would cause a HardFault on our Cortex-M4 and ultimately halt the system or capture a core dump.
void my_free(void *p) {
const size_t num_bytes = prv_get_size(p);
// Set each word to 0xbdbdbdbd
memset(p, 0xbd, num_bytes);
free(p);
}
When inspecting the core dump, the backtraces and buffer contents would show our
bad address 0xbdbdbdbd and we’d immediately know that it was a “use after
free” bug.
State Transition Errors
I’m assuming most state machine generators or best practices prevent state transition errors from happening to begin with, but if that isn’t the case, this one is important and worth putting in your state machines.
Let’s pretend we have two states, kState_Flushing, and kState_Committing,
where the commit happens after and only after a flush state. We can assert this
state change in our function as a sanity check.
void on_commit(eState prev_state) {
ASSERT(prev_state == kState_Flushing);
}
Compile-Time Programmer Errors
Developers make mistakes all the time. One defense we can put in place against
ourselves is by using static_assert3. I commonly use this is to
make sure that my structs don’t exceed a required size limit.
typedef struct {
uint32_t count;
uint8_t buf[12];
uint8_t new_value; // New field
} MyStruct;
_Static_assert(sizeof(MyStruct) <= 16, "Oops, too large!");
When I try to compile this, I get a compile time error assert:
$ gcc test.c
test.c:14:1: error: static_assert failed due to requirement
'sizeof(MyStruct) <= 16' "Oops, too large!"
_Static_assert(sizeof(MyStruct) <= 16, "Oops, too large!");
^ ~~~~~~~~~~~~~~~~~~~~~~
1 error generated.
You can use this on anything that can be statically defined, including alignment of struct fields, struct and enum sizes, and string lengths. Funny enough, I also use this when I want to force myself and others to think twice about certain changes. If I wanted to make sure that I or anyone else
_Static_assert(sizeof(MyStruct) == 16,
"You are changing the size! "
"Please refer to https://wiki.mycompany.com/... "
"to learn how to update the protocol version ...");
Thankfully, those strings don’t get included in the final firmware binary so you are free to make them as long as you like!
Handling External & Application Code
There are places where one would not want to use offensive programming practices. Primarily, it’s when the developer is not fully in control of the software, hardware, or incoming data. These could be any of the following:
- Hardware & peripheral drivers
- Contents of flash or persistent storage
- HAL or 3rd-party libraries
- Data or external inputs from comms stacks
- Language interpreters, such as MicroPython4 or JerryScript5
- 3rd party applications written by external developers
All of these variables or inputs are outside the control of the developer, and you should not trust any of them! Developers will do the most creative, beautiful, terrible, abusive, and dangerous things to your platform, unintended or not, and you should be very cautious of this.
To prevent bugs from stomping on your lawn, you can isolate these outside layers with a shim layer that uses defensive programming. This ensures that any bad inputs, corrupted data, and nefarious actors receive error codes instead of crashing the software.
One important thing, that can’t be stressed enough, is that you can almost always trust and assume that developers and code internal to your organization or project will be correct or at least want to be correct. With this in mind, we can assert everything within the Internal Software block and crash the application or system and provide useful data to internal developers.
Best Practices
Don’t Assert on Boot Sequences
Simple and sweet. Don’t assert anything on code that is run during a boot-up sequence that isn’t guaranteed, because this is how reboot loops can occur when something goes wrong. The only time I would assert on a boot sequence is when my device is connected to a debugger, or when things are absolutely required and there is zero chance of shipping a broken firmware to end-users.
When in doubt, log these errors instead.
Playing Offense Internally
There is no better time to enable asserts, watchdogs, and other OffP practices than when a development board is connected to a debugger! With this in place, developers can instantly and easily get backtraces and system state, as well as trace through the execution of the undefined behavior to find out what happened as well as potentially discover what would happen if the bug is not fixed.
Playing Offense in Production Builds
Before we dig into what aspects of OffP make sense on production builds, we need to establish that software crashes should be recorded in some way so that a developer can retrieve them at a later date. This can be some form of logging, tracing, or core dumps, or any combination of these. If we don’t have a way to record issues, we’ll never know what truly causes these issues and how often they occur.
The parts of OffP that should be kept compiled in and enabled in production builds are the ones that ensure that undefined behavior is not experienced in firmware. This includes argument validation, watchdog timeouts to detect deadlocks, bugs potentially leading to memory corruption, etc. It’s better to return the device to a known state than to limp along.
What we can often consider disabling completely are marginal issues, such as software stalls, malloc and queue failures (which are handled), and timeouts. These types of issues aren’t guaranteed to recover or go away, but they may be acceptable depending on the context and how the device is used.
If you choose to reduce the aggressiveness of the checks, consider keeping the hooks and timeouts and instead log them somewhere, rather than reset the system. For inspiration, check out ARM MBed’s Error Handling API, which keeps a circular buffer of warnings that the system has experienced in a region of RAM that is kept between reboots. The idea is that all layers of the firmware use a single error API and then developers can do what they want with them. If you have logging infrastructure in place, you can log them out on boot, or if your system is set up with core dumps, you can capture this memory region too.
For instance, we can modify our ASSERT() macro to instead log through the
logging system instead of triggering a reset when a production build is
compiled.
#if PRODUCTION_BUILD
#define MY_ASSERT(expr, msg) \
do { \
if (!(expr)) { \
/* log error to buffer */ \
} \
} while (0)
#else
#define MY_ASSERT(expr, msg) \
do { \
if (!(expr)) { \
/* core dump */ \
} \
} while (0)
#endif
Conclusion
I love when my firmware and tools work with me instead of against me. If the firmware knows that there is an issue, it should make that fact front and center and maybe even point me to a Wiki page explaining what I did wrong! This is what offensive programming is all about. If you implement these ideas into your firmware, even if only just a few of them, I promise they’ll pay dividends and you’ll be able to root cause issues more quickly than before.
I’d love to hear about any other strategies that you all take to surface bugs that are hidden in your firmware! Come find me in the Interrupt Slack.
Interested in learning more offensive and defensive programming best practices? Register for our webinar on February 24, 2022.
See anything you'd like to change? Submit a pull request or open an issue on our GitHub
References
 Tyler Hoffman has worked on the embedded software teams at Pebble and Fitbit. He is now a founder at Memfault.
Tyler Hoffman has worked on the embedded software teams at Pebble and Fitbit. He is now a founder at Memfault.